回顾完上几代产品最重点的技术改进,下面我们就来看全新第四代酷睿处理器Haswell的特性。作为TOCK代的产品,Haswell的核心架构有部分变化。这就是Haswell引入的AVX2指令集。

▲第四代智能酷睿Core i7
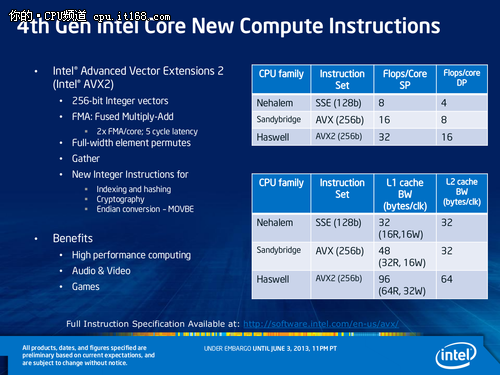
我们知道大部分应用程序主要依赖于整数运算,另外在多媒体方面浮点运算需求也显著增加,AVX2一系列的指令集的优化能够直接受益这些应用,带来更强的多媒体图形处理能力以及更流畅的应用程序体验。AVX2指令集是在AVX指令集的基础上加入了256位矢量宽度、增强的数据排序、3/4个操作数、非对齐内存存取以及VEX编码方式,显著提升了处理器的浮点计算性能。
与Sandy Bridge/Ivy Bridge架构的指令发出端口稍有不同的是,原来整数运算和浮点/SIMD运算同样通过指令端口进行分配,其中整数运算ALU单元数量为3个,载入/存储管线为2条。而现在Haswell架构指令发出端口由2个提升为8个,整数运算单位和载入/存储管线各增加1个。因此Haswell架构处理器可同时执行4个整数运算,以及2个载入和1个存储的操作。还有就是端口0和端口1各自连接的AVX(Advanced Vector Extensions)SIMD运算单元的位宽也提升至256-bit。以前端口0 AVX256-bit SIMD(MUL)和和1个AVX合并在一起,而Haswell中端口0与256-bit SIMD(FMA),端口1与256-bit SIMD(FMA)合并在一起。

AVX2指令集增强了对256bit整数SIMD的支持,新增60条256bit浮点SIMD指令,在AVX的基础上进一步完善。另外在浮点运算上,新增的FMA单元支持8个单精度或4个双精度浮点数,每周期单/双精度FLOPs都要比AVX高一倍。这些改善都显著提升了处理器的浮点和整数运算性能。
为了支撑CPU核心的吞吐量增长,Haswell缓存不属于CPU核心,属于整个CPU的L3缓存性能有一定的提高。在Haswell中数据访问和其他访问进行了分离,采用不同的流水线进行处理。对于不同核心共享的系统资源,如系统代理,改善了信用管理机制,使得系统代理的负载能够在不同的核心之间更好的分配。提高了系统内存写入的吞吐量,增加了内存写入队列的深度,可以更好的进行调度。在前面介绍Core i7 4770K规格的时候已经提到过,其相比上代产品新增了AVX2和FMA3指令集。
AVX2是由原来Sandy Bridge架构上的第一代AVX指令集扩展增强而来的,为绝大多数128位SIMD整数指令带来了256位数值处理能力,同时继续遵循AVX的编程模式。AVX2还提供了一系列增强的功能性,包括数据元素的广播(broadcast)、逆变(permute)操作,每个数据元素可变位移计数的矢量位移指令,从内存中拾取非相邻数据元素的指令等等。
另外,Haswell架构也开始支持 积和熔加 运算(Fused Multiply-Add,FMA),也就是可以在同一条指令里同时执行加法和乘法运算,可提高浮点计算速度和数字精确度,改善矢量和标量工作流的执行。
Haswell架构还有一些其它的改进,包括有内存访问带宽的大幅度提升。由于内存存取带宽的提升,必然会带来处理器性能的提升。比如L1载入带宽由原先的32-byte/循环提升为64-byte/循环。而L2和L1缓存带宽也由之前的32-byte(256-bit)提升为64byte(512-bit)。并且L2 Translation Lookaside Buffer (TLB)也获得了大幅提升,从而可以大大提升大规模work load的性能表现。
Haswell架构所有内置单元的连接和布局与Sandy Bridge/Ivy Bridge架构相似,各个核心的管线并没有什么太大变化。其中,前端指令fetch/decoding部分与之前的Sandy Bridge/Ivy Bridge非常相似。不过指令下行back-end缓存周围则有很大的不同,这个部分明显被扩大了。
关于Haswell架构,如果只用一句话来形容的话,就是以back-end为中心进行了架构改进,其指令发出/执行管线相比之前的数代(Nehalem-Sandy Bridge)架构相比,拥有了极大的变化。首先就是从Merom开始一直到Ivy Bridge架构,都一直延续着6指令运行,而现在则提升为8指令(uOPs)。

