Intel SandyBridge 接口架构再升级
2011年,又是Intel更新架构的一年,还记得在没出产品之前很多网友都在质疑到底会不会再换接口,但现在看来这些都已经是板上钉钉的事了,那就是为了继续革新架构提升性能,绝不姑息一个接口!或许正是Intel这种奔放执着的方式使其一直领跑CPU的性能巅峰。
事实上就像一句广告说的那样,没有最好,只有更好。在CPU的架构上面不可能是一成不变的。只有不断的改进、革新甚至推到重来才能获得更加强大的性能提升。Nehalem虽然是一款划时代的产品,但终究并不完美,在设计上仍然有一些瓶颈未得到突破,因此在新一代的Sandy bridge结构上,Intel又进行了大胆的修改和调整,可以说是贯穿了整个处理器流水线。
▲新的分支预测单元
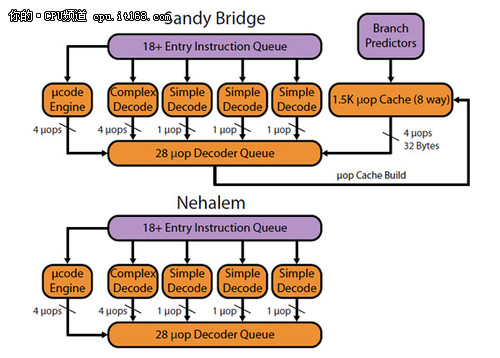
新的分支预测单元分离自取址单元,分支预测单元提高了CPU内部对嵌套语句预测的正确率和速度。众所周知,分支预测的准确率决定了指令执行的效率,对于CPU的效能提升有着至关重要的作用,尤其是现在处理器大多使用超标量流水线,乱序指令执行,如果某一条分支预测错误都会导致整个过程推到重来,白白浪费运算资源。
另外前端加入的uop cache(微指令缓存),这个部件类似NetBurst 微架构的Trace Cache(追踪缓存) 作用也相似,只是相比前者设计的更加简洁了。uop cache 可以保存已经解码的微指令,因此也可以被称为L0 ICache,容量为1.5K uops,根据英特尔的说法,通常的应用当中其命中率可以达到80%,在命中这个缓存之后,可以极大的释放前段解码单元的工作量。

▲物理寄存器架构
指令的发射和分派阶段SNB处理器也是非常的给力。首先上面这张图是Nehalem与SandyBridge的一幅物理寄存器对比图。可以看到,二者最大的不同就是PRF(Physical Register File,物理寄存器文件)和RRF(Retired Register File,回退寄存器文件)之间的差别。SNB核心的处理器能够在其寄存器文件中存贮uop微操作数,而乱序执行引擎中仅携带指向操作数的指针,这样就大大减小了数据移动所需要的电能,最终使得数据流窗口扩大了1/3,且提高了性能。
事实上通过这一改进,使得ROB(ReOrder Buffer,新排序缓存)的容量也提高到了168项,统一调度的容量也升至54个条目。相比前一代产品有了不小的飞跃,特别是在支持AVX的指令的产品中。精简的X86指令集使得CPU在执行复杂媒体指令的时候效率大大提升。
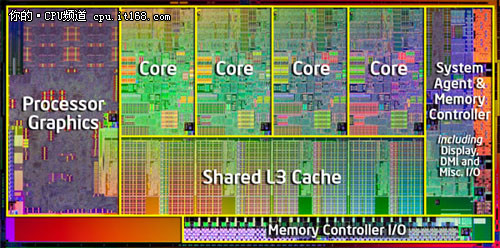
▲新的SandyBridge处理器
可以与前面Nehalem处理器晶片截图做个对比,新一代的Sandy Bridge架构集成了更加强大的系统助理模块,并且将GPU进一步集成在了CPU内部,相比Nehalem相对独立的设计,Sandy bridge则更加强了架构的统一设计,配合内部新的环形总线和末级LLC设计,使得整体性能又登上了一个台阶。
事实上SNB换装1155接口其实并不令我感到惊讶,因为GPU的整合和新模块的加入,肯定要占用一些新的接口(触点),这点毋庸置疑,算是性能优先原则吧,毕竟鱼和熊掌不可兼得。

