【IT168 技术】不久前Intel刚刚发布来基于Haswell架构的全新第四代智能酷睿处理器,而且首批上市的产品多达22款,其中光基于桌面平台的就有13款之多,包括了i7和i5两个系列。作为全新架构的Intel Core i7 4770K来说,代号Haswell的新一代处理器被消费者赋予了太多的希望,毕竟前几代产品的强悍是毋容置疑的,消费者的希望与超越前代产品的“任务”从某种程度上来说,Intel Core i7 4770K面临了前所未有的压力。

我们都知道,目前Intel采用的是“Tick-Tock”模式。“Tick-Tock”的原意是时钟走过一秒钟发出的“滴答”声响,因此也称为“钟摆”理论。按照Intel的计划,每两年进行一次架构大变动——“Tick”年(奇数年)实现制作工艺进步,“Tock”年(偶数年)实现架构更新。根据以往的经验,“Tick”年推出的产品多为工艺更新、优化的核心和指令集等等和架构微调。

自从Intel展开Tick/Tock模式来更新产品,每一代的Tock环节都备受瞩目,在大多数消费者眼里,新架构带来的改进要比制程改进对性能的提升要明显很多,特别是2011年5月3D Tri-Gate晶体管架构的启用,改变了业界,也改变了Intel自身。从Lynnfield(2009年)、Clarkdale(2010年)、Arrandale(2010年)、Sandy Bridge(2011年),以及2012年最新的Ivy Bridge,以及刚刚发布的Haswell。
作为全新第四代智能酷睿处理器,背负着这样的名号,全新的Haswell处理器携手与之配套的Lynx Point(8系列)芯片组正式开启了征程。作为TOCK代的产品,Haswell的核心架构有部分变化。这就是Haswell引入的AVX2指令集。
Haswell处理器Core i7 4770K架构解析
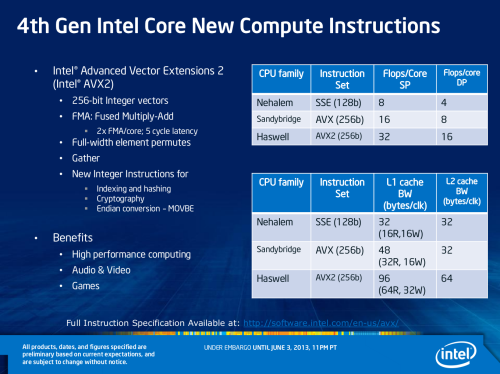
我们知道大部分应用程序主要依赖于整数运算,另外在多媒体方面浮点运算需求也显著增加,AVX2一系列的指令集的优化能够直接受益这些应用,带来更强的多媒体图形处理能力以及更流畅的应用程序体验。AVX2指令集是在AVX指令集的基础上加入了256位矢量宽度、增强的数据排序、3/4个操作数、非对齐内存存取以及VEX编码方式,显著提升了处理器的浮点计算性能。

与Sandy Bridge/Ivy Bridge架构的指令发出端口稍有不同的是,原来整数运算和浮点/SIMD运算同样通过指令端口进行分配,其中整数运算ALU单元数量为3个,载入/存储管线为2条。而现在Haswell架构指令发出端口由2个提升为8个,整数运算单位和载入/存储管线各增加1个。因此Haswell架构处理器可同时执行4个整数运算,以及2个载入和1个存储的操作。还有就是端口0和端口1各自连接的AVX(Advanced Vector Extensions)SIMD运算单元的位宽也提升至256-bit。以前端口0 AVX256-bit SIMD(MUL)和和1个AVX合并在一起,而Haswell中端口0与256-bit SIMD(FMA),端口1与256-bit SIMD(FMA)合并在一起。
AVX2指令集增强了对256bit整数SIMD的支持,新增60条256bit浮点SIMD指令,在AVX的基础上进一步完善。另外在浮点运算上,新增的FMA单元支持8个单精度或4个双精度浮点数,每周期单/双精度FLOPs都要比AVX高一倍。这些改善都显著提升了处理器的浮点和整数运算性能。
为了支撑CPU核心的吞吐量增长,Haswell缓存不属于CPU核心,属于整个CPU的L3缓存性能有一定的提高。在Haswell中数据访问和其他访问进行了分离,采用不同的流水线进行处理。对于不同核心共享的系统资源,如系统代理,改善了信用管理机制,使得系统代理的负载能够在不同的核心之间更好的分配。提高了系统内存写入的吞吐量,增加了内存写入队列的深度,可以更好的进行调度。在前面介绍Core i7 4770K规格的时候已经提到过,其相比上代产品新增了AVX2和FMA3指令集。
AVX2是由原来Sandy Bridge架构上的第一代AVX指令集扩展增强而来的,为绝大多数128位SIMD整数指令带来了256位数值处理能力,同时继续遵循AVX的编程模式。AVX2还提供了一系列增强的功能性,包括数据元素的广播(broadcast)、逆变(permute)操作,每个数据元素可变位移计数的矢量位移指令,从内存中拾取非相邻数据元素的指令等等。
另外,Haswell架构也开始支持 积和熔加 运算(Fused Multiply-Add,FMA),也就是可以在同一条指令里同时执行加法和乘法运算,可提高浮点计算速度和数字精确度,改善矢量和标量工作流的执行。

Haswell架构还有一些其它的改进,包括有内存访问带宽的大幅度提升。由于内存存取带宽的提升,必然会带来处理器性能的提升。比如L1载入带宽由原先的32-byte/循环提升为64-byte/循环。而L2和L1缓存带宽也由之前的32-byte(256-bit)提升为64byte(512-bit)。并且L2 Translation Lookaside Buffer (TLB)也获得了大幅提升,从而可以大大提升大规模work load的性能表现。
Haswell架构所有内置单元的连接和布局与Sandy Bridge/Ivy Bridge架构相似,各个核心的管线并没有什么太大变化。其中,前端指令fetch/decoding部分与之前的Sandy Bridge/Ivy Bridge非常相似。不过指令下行back-end缓存周围则有很大的不同,这个部分明显被扩大了。
关于Haswell架构,如果只用一句话来形容的话,就是以back-end为中心进行了架构改进,其指令发出/执行管线相比之前的数代(Nehalem-Sandy Bridge)架构相比,拥有了极大的变化。首先就是从Merom开始一直到Ivy Bridge架构,都一直延续着6指令运行,而现在则提升为8指令(uOPs)。 在这一代产品上,Intel改变了之前的思路,性能的改进不再是最重要的部分,功耗控制成了Haswell的重头戏。前面我们说的架构改进,只是为了下一代产品“铺路”而已,其实最重大的变化就是在CPU内部整合了FIVR电压调节模块。
重大改进:内置全新FIVR电压调节模块
在前几代的产品中,包括Ivy Bridge以及Sandy Bridge,处理器的Core VR、Graphics VR、PLL VR、System Agent VR、IO VR模块都被设计在主板上,这5个模块以FIVR模块整合到CPU内部后,使得CPU内核的供电更加精准,并带来更纯净的供电电流,提升供电效率。
FIVR模块整合的另外一个好处就是简化的CPU外部供电设计,用来精确调整CPU核心供电的技术。这项技术可以让Core 、Graphics、System Agent、PLL、IO更加独立,实现更高效的能效控制。FIVR可以独立调节处理器内部的各个模块供电,包括Core、Graphics和总线等等,也同样可以将不需要的部分关闭,如果你的任务只需要CPU核心工作,那么显卡部分就可以不参与到工作中,这将大大节省功耗。
受到工艺和成本的影响,原先的VR模块在开关速率上会对处理器的电流输出稳定带来一定的影响,整合到处理器内部的Power Cell开关频率相对与传统的主板集成式得到显著提升,从而让CPU获得更为纯净的供电电流,另外Power Cell还拥有更强的电流承受能力,按照Intel官方的介绍,每路Power Cell支持25A的电流,并且每个Power Cell支持16相的供电,一颗完成的芯片最高可以容纳320相供电。

虽然有了这项创新的FIVR电压调节模块,但并不意味着主板上的供电模组就不需要了,以目前的设计,主板供电模块供电给处理器之后由FIVR来进行二次调节,所以目前来看主板和CPU的供电模块是缺一不可的,在Haswell架构中,每个CPU内都有单独的Power Cell电路,每个Power Cell又有16相PWM电路,每个处理器内最多可有20个Power Cell单元。
从一开始我们就说Intel改变了之前的思路,新的策略在桌面平台上可能效果并不明显,但是一旦放到笔记本等移动平台,这项技术就会变得非常高效和实用,具体,请参看移动平台版本的Intel 处理器评测,相信一定会让大家大吃一惊的。
总结:小改进,大进步 intel继续为行业领导者
除了前面提到了增加了AVX2指令集之外,把电压调节模块FIVR整合到处理器中也算是创新,再辅以成熟点22nm制程以及Intel独有的3D晶体管技术,全新一代的酷睿系列处理器性能(CPU和GPU)上有了进步,但更重要的是,为将来的处理器的发展奠定了坚实的基础。

从某种意义上来说,Intel用Haswell处理器再次证明了其创新的思维和远见,即便Haswell的成功不是巨大的,但是从长远发展的角度来看,Haswell是必不可少的。Intel在行业内的领先地位也可见一斑!

