【IT168 资讯】全球各地的多台超级计算机系统已经超越了1PFLOPS(每秒一千万亿次浮点运算)的大关,下一个目标就是Exascale系统(1000PFLOPS,每秒一百亿亿次)。上周举行的SuperComputing 2010高性能计算大会上,NVIDIA首席科学家William Dally就预览了他们在这一领域的研发成果,一颗面向Exascle级别超级计算机的芯片,代号Echelon。
该项目属于美国国防部下属DARPA(国防高级研究计划署)的“普及高性能计算计划”。计划的目标是在2014年提供一台原型机架式服务器,功耗不超过57KW,性能达到1PFLOPS。下一步则是到2018年,建成达到Exascale性能的原型系统。

▲百亿亿次
目前,竞争这一项目的有来自NVIDIA、Intel、麻省理工学院和Sandia国家实验室的四组团队。William Dally在会议上表示,NVIDIA的主要着眼点是提升每瓦性能,并提供可以打造从Tegra到Tesla的各种产品的通用架构。他们计划在芯片内集成256MB SRAM,并尽量降低SRAM缓存延迟。
为了进一步降低功耗,NVIDIA团队引入了根据不同应用需要的动态配置设计。目前,他们已经将每次浮点运算的功耗从Fermi架构的200皮焦,下降到Echelon 32nm试验架构下的10皮焦。
当然,目前Echelon还只是停留在设计图纸和计算机模拟阶段的概念产品。其架构包括128个流式多处理器单元(SMU),每个SMU包含8个64-bit浮点运算核心(每个核心在一个时钟周期内可进行4次双精度浮点运算)。根据估算,1024个核心的Echelon芯片运算能力在10TFLOPS左右。而该芯片的手机版本将只有一组SMU,8个核心,双精度浮点运算能力78MFLOPS。
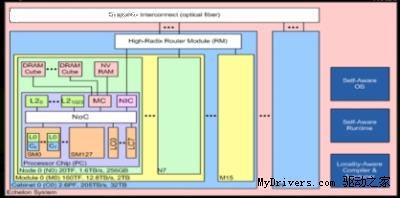
▲架构图
和目前的架构相比,Echelon 1024个流处理单元的数量是Fermi的两倍,而且其核心在一个时钟周期内可进行4次双精度浮点运算,现有架构只有1次。
和x86多核心处理器遇到的挑战一样,在1024核芯片上编程的难度可想而知。Dally承认在编程模型方面大家肯定会遇到海量的问题,而解决这些问题将成为未来10年甚至更长时间中的主要工作。

